今天,我看到了一个让我觉得激动人心的重大更新,Gemini 2.5 Flash Image (也叫 nano-banana ) 在 Gemini API 和 Google AI Studio(面向开发者)以及 Vertex AI(面向企业)提供。定价为 每百万输出 token $30,每张图像约为 1290 输出 token(约 $0.039/张图像)。
目前可以免费有限的体验。
Gemini 2.5 Flash Image 是 Google 最新的图像生成与编辑模型,支持多图像融合、角色一致性、自然语言局部编辑和世界知识增强。
主要功能和增强:
-
角色一致性: 能够在多个提示和编辑中保持角色或物体外观的一致性,适用于讲故事、产品展示和品牌资产生成。
-
基于提示的图像编辑: 允许通过自然语言进行有针对性的转换和精确的局部编辑(如模糊背景、移除物体、改变姿势、添加颜色等)。
-
原生世界知识: 利用Gemini的世界知识,实现对现实世界的深度语义理解,解锁新的用例,例如理解手绘图表、回答现实问题和执行复杂编辑指令。
-
多图像融合: 能够理解和合并多个输入图像,实现物体放入场景、房间风格改造和图像融合等功能。
我第一时间就上手体验了。
1. Gemini App
打开 Gemini App / Web , 把模型切换成 2.5 Flash,点击图片图标,输入提示词,等待生成。
2. Google AI Studio
打开 Google AI Studio,在聊天界面选择 Gemini 2.5 Flash Image Preview 模型。
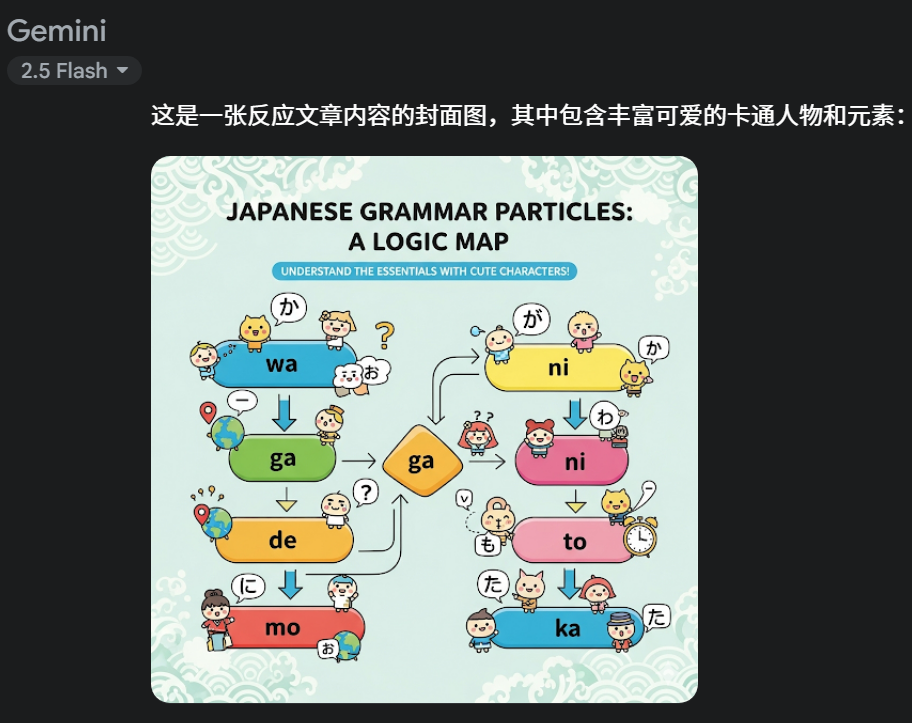
生成封面图
我让它总结一篇英语文章的内容,生成封面图,效果不错:

以下是提示词:
总结以下文章的内容要点, 生成反应文章内容的封面图, 要求:
- 信息图
- 加上丰富可爱的卡通人物和元素
- 先思考后生成
文章内容[]
生成手办模型
X上 ZHO 大佬的手办提示词这几天都火了吧,我把它改了一下,一次上传3张图,让它生成:

看起来还是挺真实的。以下是提示词:
turn this photo[图1] into a character figure. Behind it, place a box with the character’s image[图3] printed on it, and a computer showing a wallpaper[图2] on its screen. In front of the box, add a round plastic base with the character figure standing on it. set the scene indoors if possible
生成逻辑图
但是,让我沮丧的是,对于非英文文字生成的支持还不是很好,比如我让它根据提供的文字生成逻辑图。

它生成的图片是:
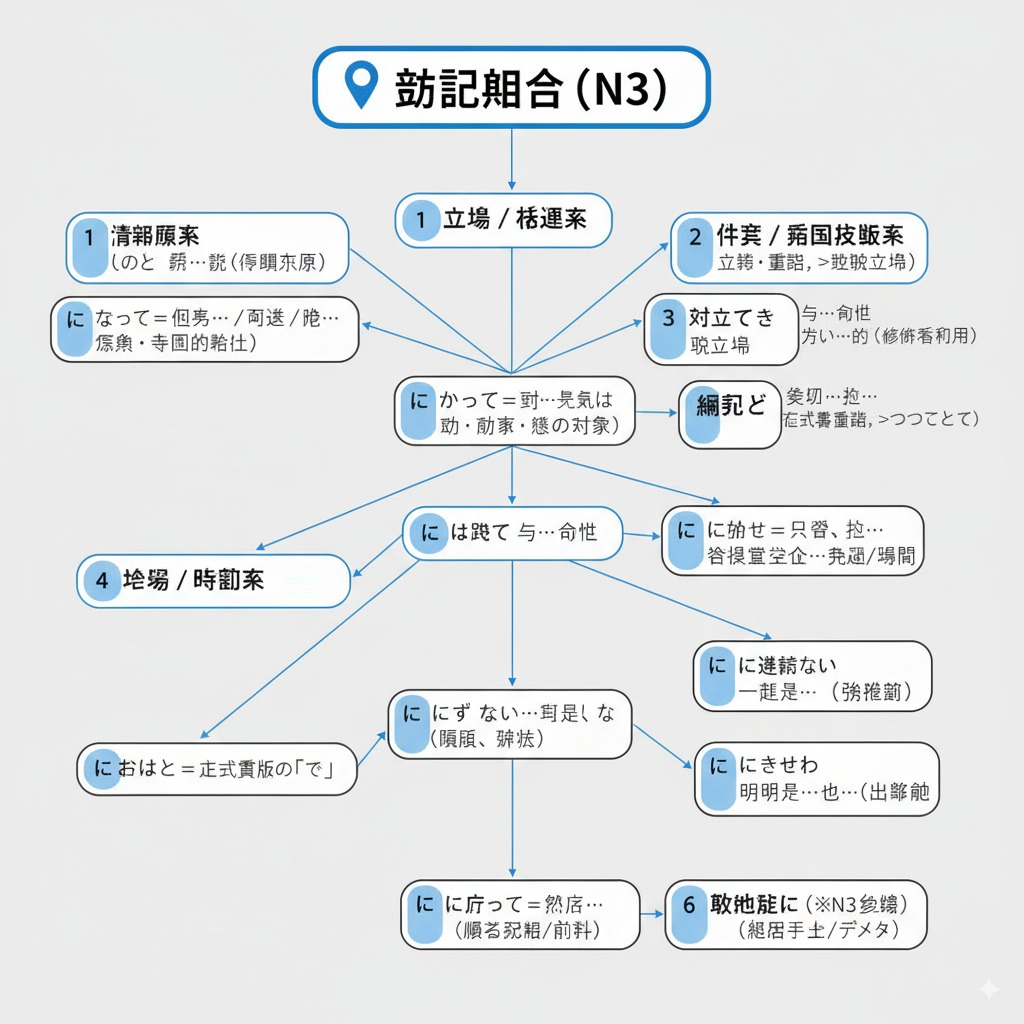
期待以后能在文字支持上更多样化~